
ERNIE 논문 설명(ERNIE 3.0 - Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation)
28 Jul 2021 | Paper_Review NLP ERNIE목차
- ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation
- 초록(Abstract)
- 1. 서론(Introduction)
- 2. 관련 연구(Related Work)
- 3. ERNIE 3.0
- 4. 실험(Experiments)
- 5. 분석(Analysis)
- 6. 결론(Conclusion)
- 참고문헌(References)
이 글에서는 Baidu에서 만든 모델 시리즈 ERNIE 중 다섯 번째(ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation)를 살펴보고자 한다.
ERNIE 시리즈는 다음과 같다. 참고로 2번째는 Baidu가 아닌 Tshinghus University에서 발표한 논문이다.
- ERNIE: Enhanced Representation through Knowledge Integration, Yu sun el al., 2019년 4월
- ERNIE 2.0: A Continual Pre-training Framework for Language Understanding, Yu Sun et al., 2019년 6월
- ERNIE-ViL: Knowledge Enhanced Vision-Language Representations Through Scene Graph, Fei Yu et al., 2019년 6월
- ERNIE-Doc: A Retrospective Long-Document Modeling Transformer, Siyu Ding et al., 2020년 12월
- ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation, Yu Sun et al., 2021년 7월
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation
논문 링크: ERNIE 3.0: Large-Scale Knowledge Enhanced Pre-Training For Language Understanding And Generation
초록(Abstract)
사전학습 모델은 다양한 자연어처리 문제에서 SOTA 결과를 얻었다. T5, GPT3은 사전학습 모델을 크게 키우는 것이 그 일반화 성능을 높일 수 있음을 보였다. 특히 GPT3 모델은 175B개의 parameter를 사용, task-agnostic zero/few-shot 학습능력이 강력함을 보였다. 이러한 성공에도 불구하고 이러한 대규모 모델은 언어적/실제 세계의 지식에 대한 정보 없이 plain text에서 학습되었으며 대부분 자동회귀 방식으로 학습된다. 그 결과로 전통적인 미세조정 접근법은 downstream 언어이해 문제를 풀 때 상대적으로 낮은 성능을 보인다. 이러한 문제를 해결하기 위해, 대규모 지식강화 모델을 사전학습하기 위한 통합 framework ERNIE 3.0을 제안한다. 이는 자동회귀 및 자동인코딩 network를 결합하여 학습된 모델이 언어이해 및 생성 문제에서 zero/few-shot 학습 및 미세조정에서 더 쉽게 조정될 수 있다. 본 논문에서 4TB의 말뭉치 및 지식 그래프를 갖고 10B의 parameter를 가지는 모델을 학습하였다. 실험 결과는 54개의 중국어 자연어처리 문제와 영어에서는 SuperGLUE에서 1등을 달성하였으며 이는 사람과 비교하여 0.8%만큼의 우위를 보인다(90.6% vs. 89.8%).

1. 서론(Introduction)
ELMo, GPT, BERT, ERNIE 1.0과 같은 사전학습 모델은 감정분류, 자연어추론, 텍스트 요약, 명명 객체 인식 등의 다양한 자연어처리 문제에서 효과적으로 성능을 높였다. 일반적으로, 사전학습 모델은 대규모 텍스트 데이터로부터 선학습한 뒤 downstream task에서 미세조정하거나 바로 zero/few-shot 학습에 사용된다. 이러한 사전학습 모델은 자연어처리 문제에서 새로운 패러다임이 되었다.
최근의 연구 동향은 이러한 모델의 크기를 크게 키워 perplexity를 낮추고 더 좋은 성능을 얻는 것이었다. Megatron-LM, T5, GPT3 등은 단순하면서도 효율적인 (거대한) layer를 여러 개 쌓아 만든 것으로 10B, 175B 정도의 parameter를 갖는다. 후에 나온 Switch-Transformer는 1T(1조) parameter 정도 크기를 갖는다.
그러나 이러한 모델은 단지 plain text에서 학습된다. 단순 텍스트는 언어적 지식과 실제 세계의 지식이 부족하여 이러한 데이터로 학습하는 것은 성능이 많이 좋아지지 않는다.
본 연구에서는 이러한 하나의 자동회귀 framework로 인해 발생하는 문제를 해결하고 지식을 추가한 사전학습 모델의 성능을 탐색하는 것으로 대규모 단순 텍스트(4TB)와 대규모 지식 그래프를 사용하여 학습하는 통합 framework인 ERNIE 3.0을 제안한다. 이는 자연어처리 및 생성 문제, zero/few-shot 학습을 모두 다루며 여러 task에도 적용될 수 있다. 이 방법은 여러 task에서 기능하는 어휘적, 구문, 의미적 정보를 인코딩하는 것이 가능하며 새로운 task가 추가되면 이 framework는 이전에 학습된 parameter에 기초하여 분산표현을 점층적으로 학습시켜 사용하며 이는 scratch로부터 새로 학습할 필요가 없음을 의미한다.
요약하면, 이 논문이 기여한 바는:
- 통합 framework ERNIE 3.0을 제안한다. 자동회귀 및 자동 인코딩 network를 결합하여 학습된 모델이 zero/few-shot 학습 혹은 미세조정을 통해 자연어이해 및 생성 문제를 다룰 수 있게 한다.
- 10B개의 parameter를 갖는 지식 강화된 모델을 사전학습하여 자연어이해 및 생성 task에서 실험하였다. 결과는 ERNIE 3.0이 54개의 중국어 task 및 SueprGLUE에서 일관되게 타 모델을 능가함을 보여준다.
2. 관련 연구(Related Work)
2.1 Large-scale Pre-trained Models
BERT 이후로 자연어이해 문제에서는 사전학습 모델이 새로운 패러다임이 되었다. 이후로는 더 낮은 perplexity를 지니는 더욱 더 큰 모델이 계속해서 나오게 되었다. 그러나 GPT3과 같은 모델은 일반상식이 부족하다. 1T개의 parameter를 갖는 Switch Transformer는 더 적은 학습 비용으로 모델을 향상시키고자 했으며 다른 연구에서는 학습 복잡도, 통신비용, 학습 불안정성 등을 해결하고자 하였다. 위의 모델들 이외에도 Chinese Pre-trained Language Model(CPM), M6, PangGu-$\alpha$ 등 비 영어 모델이 여럿 제안되었다. 중국어 모델 이외에도 204B개의 parameter를 가지는 한국어 모델 HyperCLOVA가 제안되어 GPT3보다 6500배 많은 한국어 데이터를 사용하여 학습하였다.
종합적으로 대규모 사전학습 모델이 학계와 산업계에서 높은 성능을 보이며 주목받고 있다.
2.2 Knowledge Enhanced Models
사전학습 언어모델은 대규모 말뭉치로부터 구문, 의미적 지식을 학습하지만 실세계의 지식은 부족하다. 최근, 사전학습 모델에 이러한 상식을 부여하고자 하는 시도가 여럿 있었는데 대표적으로 지식 그래프를 사용하는 방법이 있다. WKLM, KEPLER, CoLAKE, ERNIE 1.0, CALM, K-Adapter 등이 발표되었다.
3. ERNIE 3.0
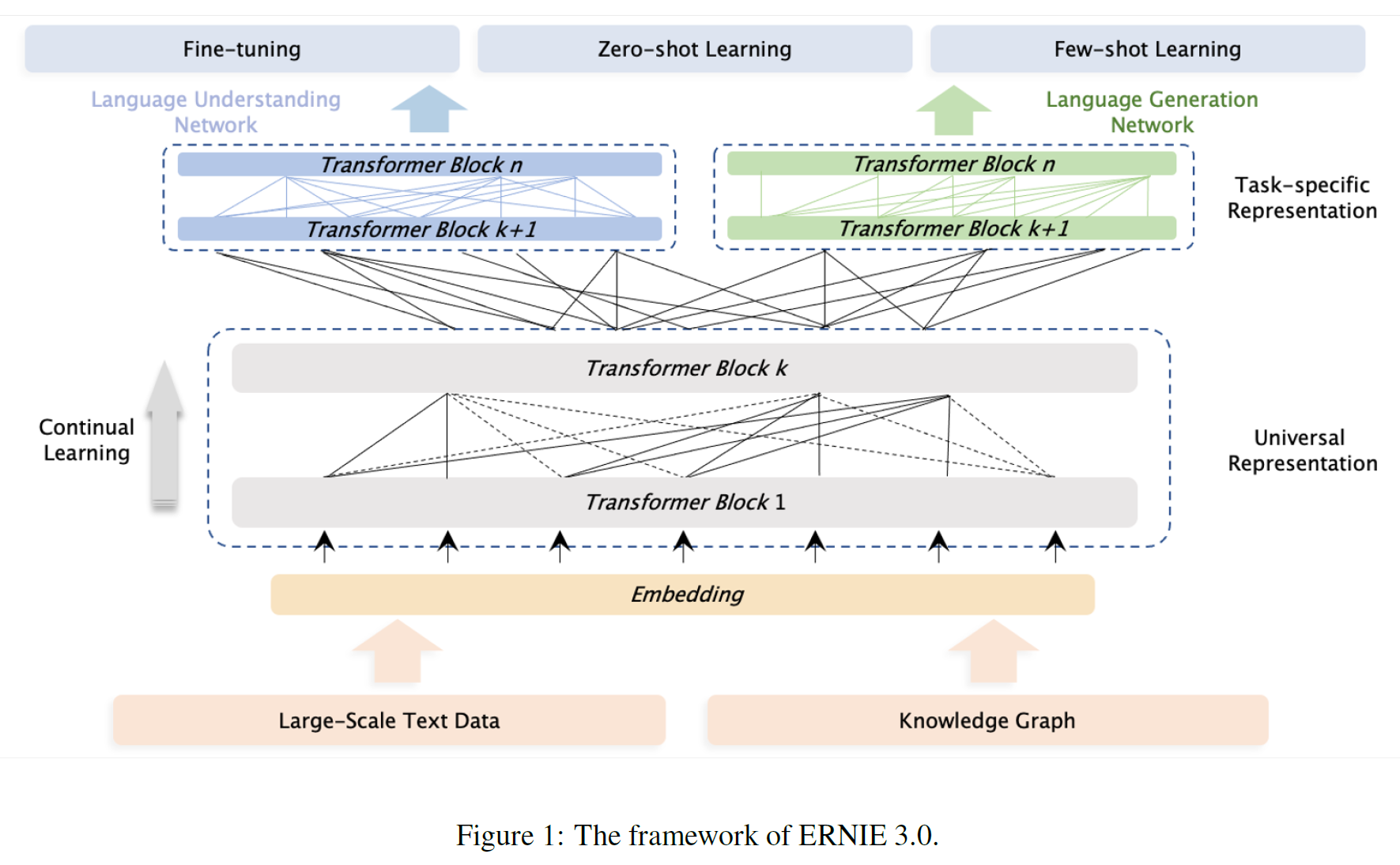
ERNIE, ERNIE 2.0, SpanBERT 등은 base/large 모델을 각각 12/24 layer의 Transformer로 구성하고 있다. 대규모 말뭉치와 지식 그래프로 사전학습한 모델 ERNIE 3.0 framework를 제안한다. 서로 다른 수준의 지식을 얻기 위해 다양한 사전학습 task를 구성하였다. ERNIE 3.0은 Continual Multi-Paradigms Unified Pre-training Framework이다.
3.1 Overview of ERNIE 3.0 Framework
일반적인 사전학습 방식은 cloze task를 위해 공유 Transformer 네트워크를 사용하고 예측 조건이 어떤 문맥에 있는지 제어하기 위해 특정 self-attention mask를 사용하지만 ERNIE 3.0은 새로운 연속 다중 패러다임 통합 사전 훈련을 설계한다.
어휘, 구문 정보를 일관되게 추출할 수 있는 방식에 의존하지만 top-level feature의 요구사항은 양립할 수 없다. 전통적인 방식에서 하단 layer는 모든 task에서 공유되고 상단 layer는 task에 특화된 방식으로 사용되며, 이에 착안하여 ERNIE 3.0은 공유 network에서 학습된 추상 feature를 공유하고 task-specific feature는 task-specific network에서 학습된 것을 사용한다. 모델이 표현을 더 잘 사용할 수 있도록 ERNIE 2.0에서 제시한 연속적 multi-task 학습 framework를 사용한다.
Downstream task로의 응용은 ERNIE 3.0을 사전학습된 공유 네트워크 및 task-specific 네트워크를 결합한 것으로 최적화하여 특정 task의 data를 사용하여 실행하는 과정을 따른다.
ERNIE 3.0에서 Backbone 공유 네트워크와 task-specific 네트워크는 Universal Representation Module과 Task-specific Representation Modules으로 칭한다.
- Universal Representation Module은 범용 semantic feature 추출기로서 작동하며(multi-layer Transformer가 될 수 있다) 모든 task에서 공유되는 parameter이다.
- Task-specific Representation Modules는 task-specific feature를 추출하는 부분으로 task마다 다른 parameter를 가진다.
이러한 방식으로 대규모 사전학습 모델은 제한된 시간과 자원 하에서 사용하기 어려운 것을 ERNIE 3.0은 task-specific 네트워크 부분만 업데이트함으로써 이를 가능케 한다. ERNIE 3.0은 1개의 Universal 모듈과 2개의 Task-specific 모듈(NLU & NLG specific representation module)을 사용한다.
3.1.1 Universal Representation Module
XLNet, Segatron, ERNIE-Doc과 같이 Multi-layer Transformer-XL을 backbone으로 사용한다. 일반적으로, Transformer는 self-attention을 통해 sequence의 각 token에서 문맥 정보를 잡아낼 수 있고 문맥 임베딩의 sequence를 생성할 수 있다. 그 크기가 커질수록 더 많고 더 다양한 많은 정보를 담을 수 있다. 따라서 ERNIE 3.0은 다양한 사전학습 task의 학습 데이터로부터 어휘적, 구문 정보를 잡아내기 위해 큰 크기의 universal 표현 모듈을 사용한다. 그리고 특히 attention이 필요한 부분은 attention mask matrix를 제어하는 동안 자연어생성 task에만 유효한 메모리 모듈이다.
3.1.2 Task-specific Representation Module
범용모듈과 비슷하게 multi-layer Transformer-XL을 사용하며 이는 서로 다른 task paradigm을 위한 상단부 의미표현을 잡아내기 위한 것이다. 기본 모델로 MLP나 shallow Transformer 대신 적정 크기의(manageable) 표현 모듈을 사용하였는데 이는 3가지 장점을 갖는다:
- 의미정보를 잡아내는 능력이 더 뛰어나다.
- Parameter의 수를 크게 늘리지 않고도 서로 다른 task paradigm 중에서 상단부 의미정보를 구별할 수 있도록 해 준다.
- 공유 네트워크보다 더 작은 크기의 task-specific 네트워크는 task-specific 표현모듈만을 미세조정했을 때보다 대규모 사전학습 모델을 위한 실용적, 실제적 응용에 더 적합하다.
ERNIE 3.0에서는 2개의 task-specific 표현모듈을 사용하였고 이는 각각 NLU 및 NLG specific representation module인데, 전자는 양방향 모델이고 후자는 단방향이다.
3.2 Pre-training Tasks
학습 말뭉치로부터 여러 방면의 정보를 얻기 위해 다양한 task paradigm을 구성하여 이해/생성/추론능력을 증가시켰다.
3.2.1 Word-aware Pre-training Tasks
Knowledge Masked Language Modeling: ERNIE 1.0에서 지식통합을 통해 표현을 증강시키는 효율적인 방법으로 제시되었다.
Document Language Modeling: 생성적 사전학습 모델은 보통 전통적인 언어모델이나 seq-to-seq 언어모델을 사전학습 task로 사용하는데, 후자는 auxiliary decoder 구조와 같이 네트워크를 학습한다. ERNIE 3.0은 전통적 언어모델을 선택하여 모델복잡도를 낮추고 통합 사전학습의 효율성을 높였다. 추가로, ERNIE 3.0의 NLG 네트워크를 모델의 더 긴 텍스트에 활용하기 위해 ERNIE-DOc에서 제안된 Enhanced Recurrence Memory Mechanism을 사용, shifting-one-layer-downwards recurrence를 same-layer recurrence로 바꿈으로써 전통적인 재귀 Transformer보다 더 효율적인 문맥길이를 모델링한다.
3.2.2 Structure-aware Pre-training Tasks
Sentence Reordering: ERNIE 2.0에서 제안된 task로 모델은 순서가 뒤바뀐(permuted) 문장들의 원래 순서를 찾아내야 한다.
Sentence Distance: NSP(Next Sentence Prediction) task의 확장판으로 문장 간의 관계를 3가지 분류(인접 문장/인접하지는 않았으나 같은 문서 내에 존재/서로 다른 문서에 존재) 중 하나로 특정해야 한다.
3.2.3 Knowledge-aware Pre-training Tasks
Universal Knowledge-Text Prediction: 하나의 사전학습된 언어모델에 지식을 통합하기 위해, 지식 마스크 언어모델링의 확장판인 UKTP(Universal Knowledge-Text Prediction) task를 도입하였다. 지식 마스크 언어 모델링에는 plain text만 필요하지만 범용 지식 텍스트 예측 작업에는 plain text와 지식 그래프가 모두 필요하다.
범용 지식 텍스트 예측 작업은 아래 그림에서 볼 수 있다.
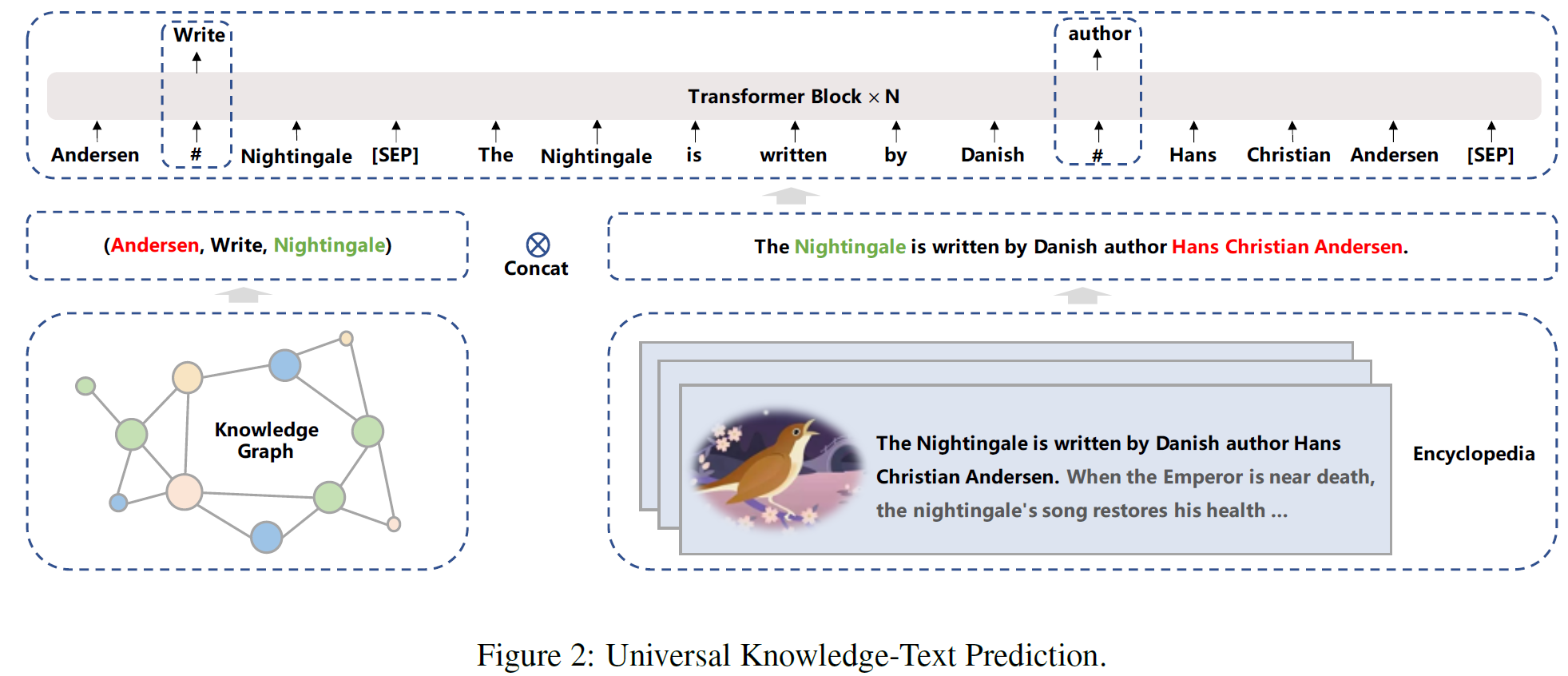
지식 그래프의 triplet 쌍과 백과사전에서 얻은 대응되는 문장이 주어지면, 모델은 head/Tail Entity를 탐지하고 대응 문장에서 그것들의 관계를 판별해야 한다. 이 과정의 본질은 관계 추출 task에서 distant 지도 알고리즘과 비슷하다. Distant 지도 알고리즘은 두 entity가 어떤 관계에 참여하면, 해당 entity를 포함하는 어떤 문장이든 그 관계를 표현할 것이라고 가정한다.
한편, 대응 문장에서 단어를 예측하기 위해, 모델은 문장 내에서 의존정보뿐 아니라 triple 안에서 논리적 관계를 고려해야 한다. 구체적으로, triple과 해당 문장의 쌍을 구하는 과정은 다음과 같다: 백과사전에서 문서가 주어지면, 지식 그래프에서 head/tail entity에 대한 언급이 문서의 제목이 되는 후보 triple을 먼저 찾은 다음, 문서의 동일한 문장에서 해당 entity들이 언급된 후보 triple 중에서 선택한다.
ERNIE 3.0은 지식 마스크 언어 모델링을 통해 NLU 네트워크를 훈련하여 어휘 정보 캡처 능력을 향상시키고, sentence reordering task와 sentence distance discerning task를 훈련하여 구문 정보 캡처 능력을 강화하고, 지식 기억 및 추론능력을 향상시기키 위해 UKTP task를 통해 모델을 최적화한다.
한편, ERNIE 3.0은 다양한 생성 스타일을 갖추도록 문서 언어 모델링 작업으로 NLG 네트워크를 학습시킨다.
3.3 Pre-training Process
3.3.1 Pre-training Algorithm
점진적 학습은 원래 효율적이고 작은 모델에서 시작하여 점차적으로 용량을 늘리는 안정성 향상을 위해 제안된 방법으로 최근 연구에서는 이 패러다임을 활용하여 모델 학습을 가속화한다. 대규모 사전학습이 계속해서 SOTA를 발전시키면서 그 엄청난 계산량은 강력한 모델을 개발함에 있어 더 큰 부담이 되고 있다.
Transformer에서 점진적 사전학습의 적용이 이루어졌는데, BERT는 처음 90%의 업데이트 동안 sequence의 길이를 줄인 2단계 학습 방법을 적용하고, batch size를 점차 큰 크기로 늘려가는 방법을 사용하였다.
또한 input 크기와 관련하여 정규화 인자를 조절하는 것도 학습 속도를 높이는 데 도움을 주는 것이 알려져 있다. 본 논문에서는 수렴 속도를 향상시키기 위해 sequence 길이, batch size, learning rate, dropout rate 등을 점진적으로 동시에 조정하는 것을 제안한다.
3.3.2 Pre-training Data
대규모, 다양성, 고품질의 중국어 데이터를 11개의 다른 종류, 4TB의 용량에 달하는 텍스트 말뭉치를 구성하였다. 이는 CLUECorpus2020(100GB), WuDaoCorpus2.0(2.3TB), PanGu Corpus(1.1TB) 등보다 더 큰, 가장 대규모의 데이터셋이다.
구체적으로, ERNIE 2.0에 기반하여, Baidu Search, Web text, QA-long/short, Poetry & Couplet, 의학/법/경제 영역 데이터 등에서 데이터를 수집하였고, 품질을 높이기 위해 다음 전처리를 수행하였다.
- 중복을 제거하기 위해,
- 문자 단위에서 연속적으로 동일한 문자(공백, 특수문자 등)을 하나로 통합하였다.
- 문단 단위에서 $N$개의 문장으로 구성된 연속 문장을 포함하는 2개의 동일한 문단을 하나로 통합한다.
- Message Digest Algorithm5(MD5)를 사용, 가장 긴 top-3 문장의 합을 비교, 중복 문서를 제거한다.
- 10개 단어보다 적은 문장은 불완전할 수 있기 때문에 제거되었다.
- Baidu의 단어 분절 도구를 사용, 문장 segmentation 작업을 수행하였다. 이는 문장 및 명명 객체의 경계를 학습하는 데 도움을 줄 것이다.

3.3.3 Pre-training Settings
Backbone network로 Transformer-XL을 사용한다.
- Universal representation module의 경우 48 layers, 4096 hidden units, 64 heads이다.
- Task-specific representation module의 경우 12 layers, 768 hidden units, 12 heads이다.
전체 parameter 수는 10B이다.
활성함수는 GeLU, 문맥의 최대길이는 512, 생성 문장의 최대길이는 128, 모든 사전학습 task의 총 batch size는 6144, Adam($lr=1e-4, \beta_1=0.9, \beta_2=0.999$), L2($decay=0.01$), lr warmup은 1만 step이다.
모델은 PaddlePaddle framework 하에서 384개의 NVIDIA v100 GPU를 사용하여 총 375B개의 token을 학습하였다. Parameter 공유를 통해 모델의 크기를 줄이고 하나의 GPU에 들어갈 수 있도록 하였다.
4. 실험(Experiments)
SOTA와 비교, 4.2.1에서 자연어이해, 4.2.2에서 자연어생성, 4.3에서 zero-shot 학습을 살펴본다.
4.1 Evaluation Tasks
54개의 자연어처리 문제를 비교한다.
4.1.1 Natural Language Understanding Tasks
14종류의 45개의 데이터셋을 사용하였다.
- Sentiment Analysis: NLPCC2014-SC 6, SE-ABSA16_PHNS 7, SE-ABSA16_CAME, BDCI2019 8.
- Opinion extraction: COTE-BD, COTE-DP, COTE-MFW.
- Natural Language Inference: XNLI, OCNLI, CMNLI.
- Winograd Schema Challenge CLUEWSC2020.
- Relation Extraction: FinRE, SanWen.
- Event Extraction: CCKS2020 9.
- Semantic Similarity: AFQMC, LCQMC, CSL, PAWS-X, BQ Corpus.
- Chinese News Classification: TNEWS 10, IFLYTEK, THUCNEWS 11, CNSE, CNSS.
- Closed-Book Question Answering: NLPCC-DBQA 12, CHIP2019, cMedQA, cMedQA2, CKBQA 13, WebQA.
- Named Entity Recognition: CLUENER, Weibo, OntoNotes, CCKS2019 14.
- Machine Reading Comprehension: CMRC 2018, CMRC2019, DRCD, DuReader, Dureaderrobust, Dureaderchecklist, Dureaderyesno 15, C3, CHID.
- Legal Documents Analysis: CAIL2018-Task1, CAIL2018-Task2.
- Cant Understanding: DogWhistle Insider, DogWhistle Outsider.
- Document Retrieval: Sogou-log.
4.1.2 Natural Language Generation Tasks
7종류의 9개의 데이터셋을 사용하였다.
- Text Summarization: LCSTS
- Question Generation: KBQG 16, DuReader-QG, DuReaderrobust-QG.
- Closed-Book Question Answering: MATINF-QA.
- Math: Math23K.
- Advertisement Generation: AdGen.
- Translation: WMT20-enzh.
- Dialogue Generation: KdConv.
4.2 Experiments on Fine-tuning Tasks
4.2.1 Fine-tuning on Natural Language Understanding Tasks
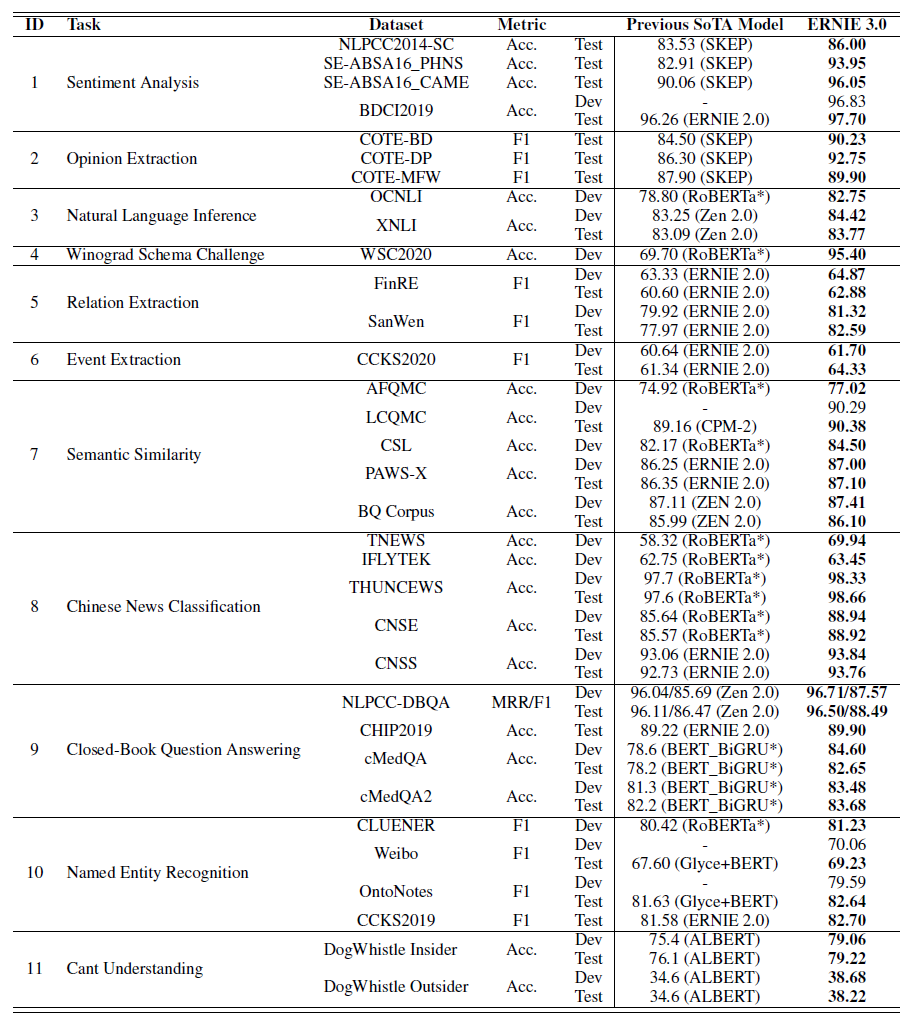
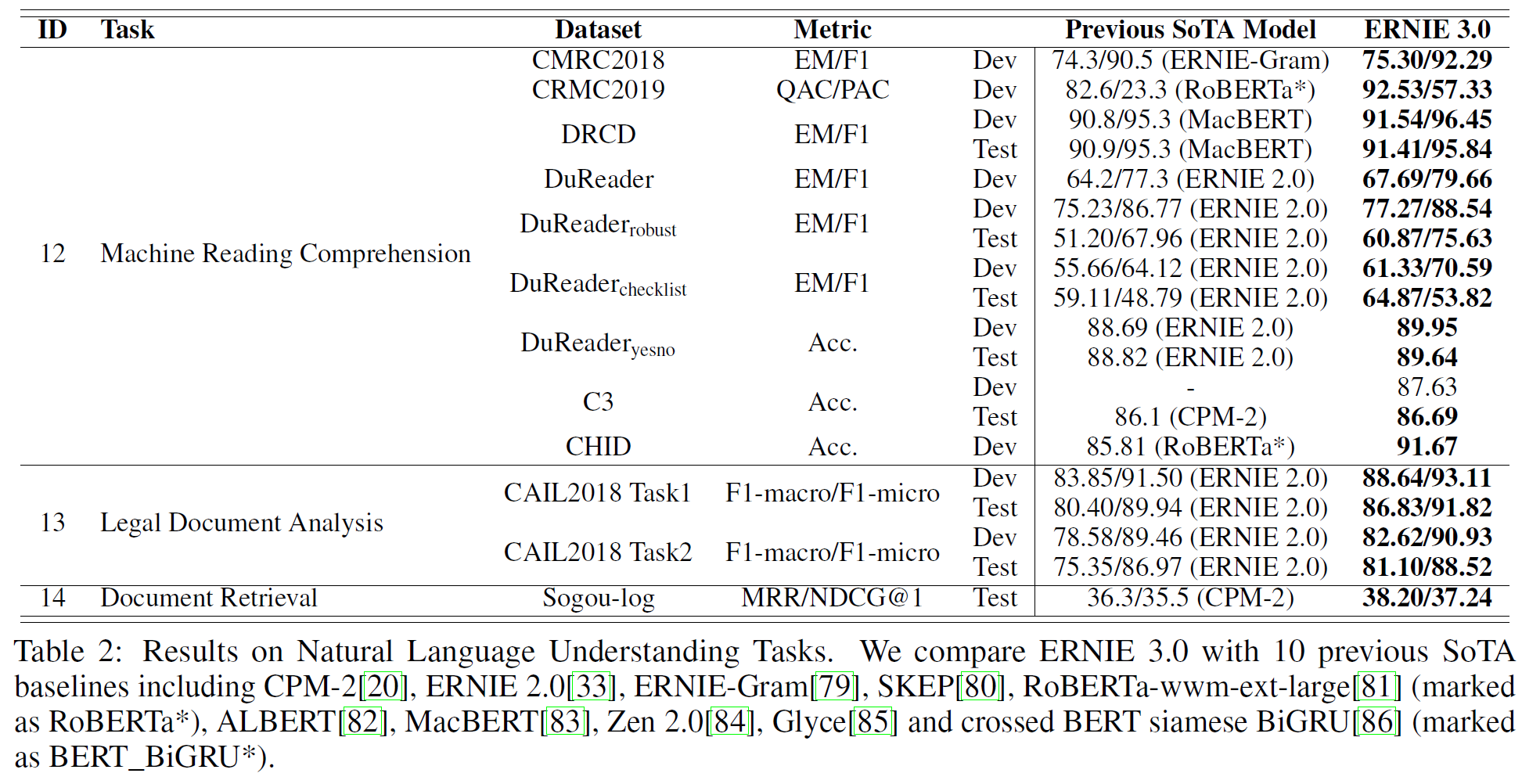
원 논문에는 각 task별로 간단한 설명이 있는데, 각 task가 어떤 task인지를 한 문장 정도로 설명하고 나머지는 ERNIE 3.0이 얼마의 차이로 가장 좋은 성능을 내었다는 설명이 있다. 자세한 내용은 위 표를 보면 알 수 있기 때문에 여기서는 생략한다.
4.2.2 Fine-tuning on Natural Language Generation Tasks
참고로 Math는 간단한 산술연산을 수행하는 능력을 평가한다. 이는 계산기를 구현한 것이 아니라 모델이 실제로 식을 보고 답을 계산하는 것을 평가하는 것이다. 실제로 데이터셋이 이렇게 구성되어 있지는 않지만, 주어지는 문제가 1+3=?이 아니라 1에다가 3을 더하면 얼마인가?를 이해하고 푸는 문제라고 대략 이해하면 된다.
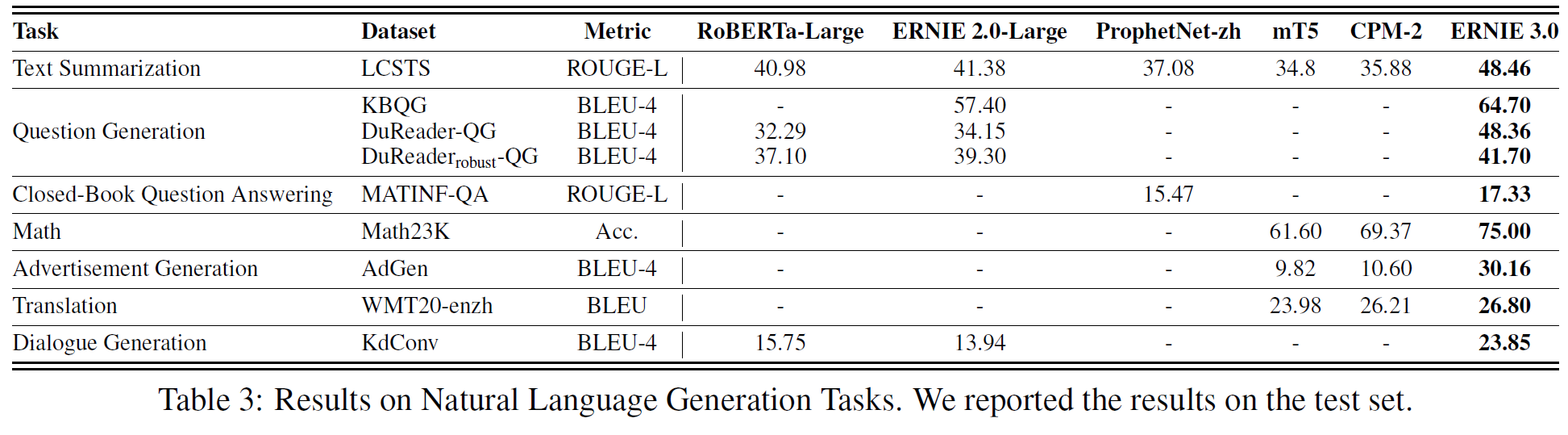
4.2.3 LUGE benchmark
Language Understanding and Generation Evaluation Benchmark라는 벤치마크로 여기서는 6개의 representative task를 사용하였다.
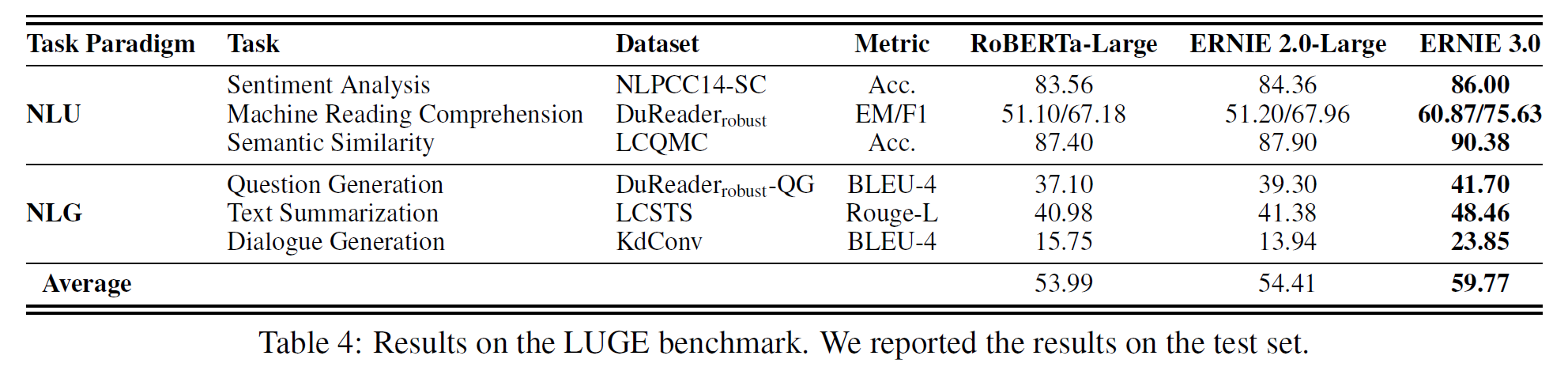
ERNIE 2.0과 RoBERTa에 비해 5.36%의 차이를 보인다.
4.3 Experiments on Zero-shot Learning
어떤 gradient 업데이트나 미세조정 없이 zero-shot만으로 ERNIE 3.0이 얼마만큼의 성능을 내는지를 평가한다.
4.3.1 Evaluation
크게 2가지로 평가 방법을 나눌 수 있다.
- Perplexity-based Method: 다지선다형 문제에서 구문 내에서 빈칸을 각 선택지로 채웠을 때 token당 perplexity 점수를 비교한다. 물론 정답일 때 perplexity 점수가 가장 낮은 값을 가진다. 분류 문제의 경우, 좀 더 의미가 있는 이름을 각 분류에 붙인 뒤 multi-choice task로 취급하여 평가한다.
- Generation-based Method: Closed-book QA와 같이 자유양식 문제의 경우 beam width 8의 beam search를 사용한다. 최대 생성 길이는 데이터셋의 상위 95%의 정답 길이로 제한된다. 이후 metric은 EM(exact match), F1, Rouge-1이 사용된다.
4.3.2 Results
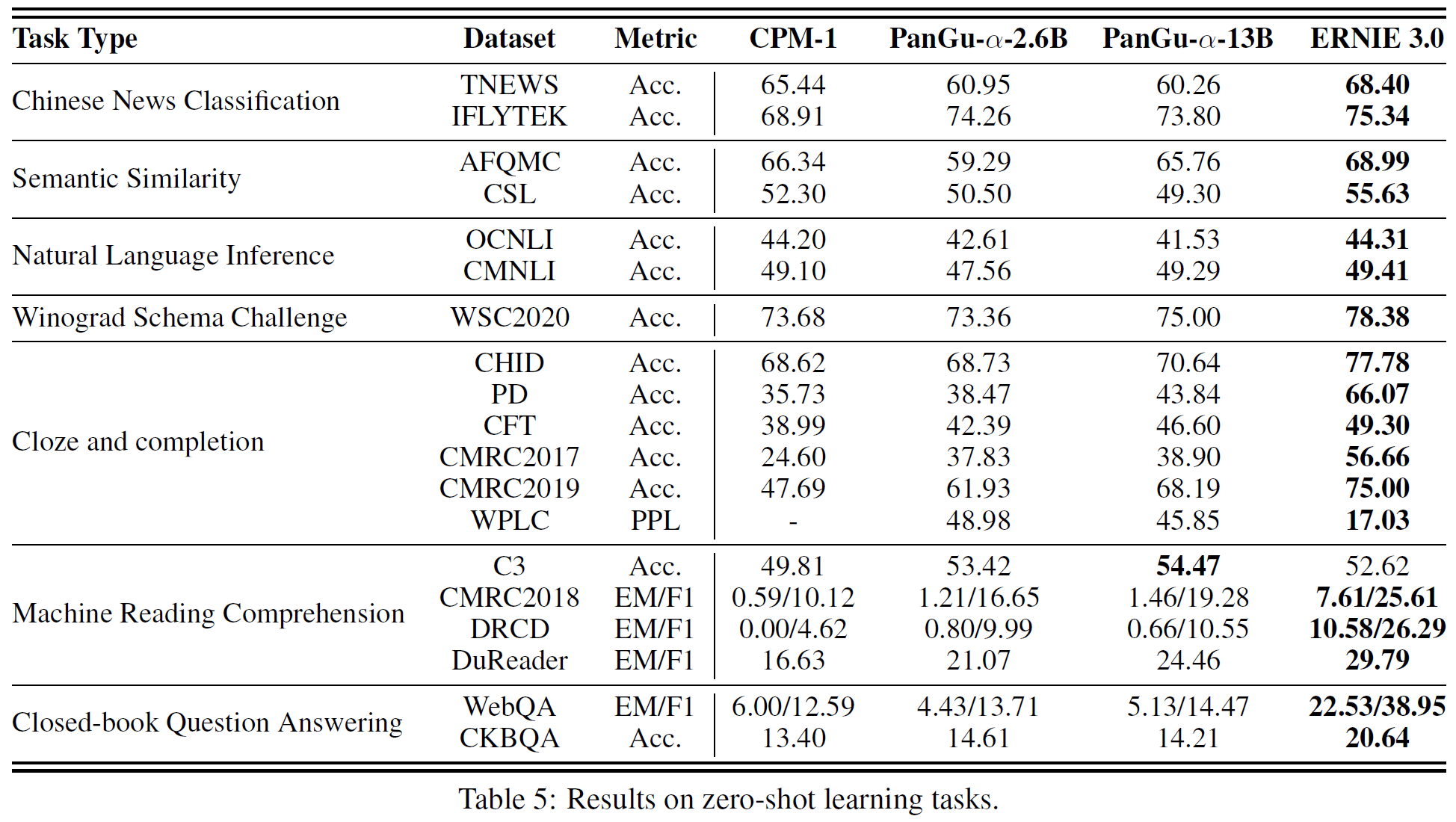
C3 task를 제외하고는 모든 부분에서 가장 좋은 성능을 보인다.
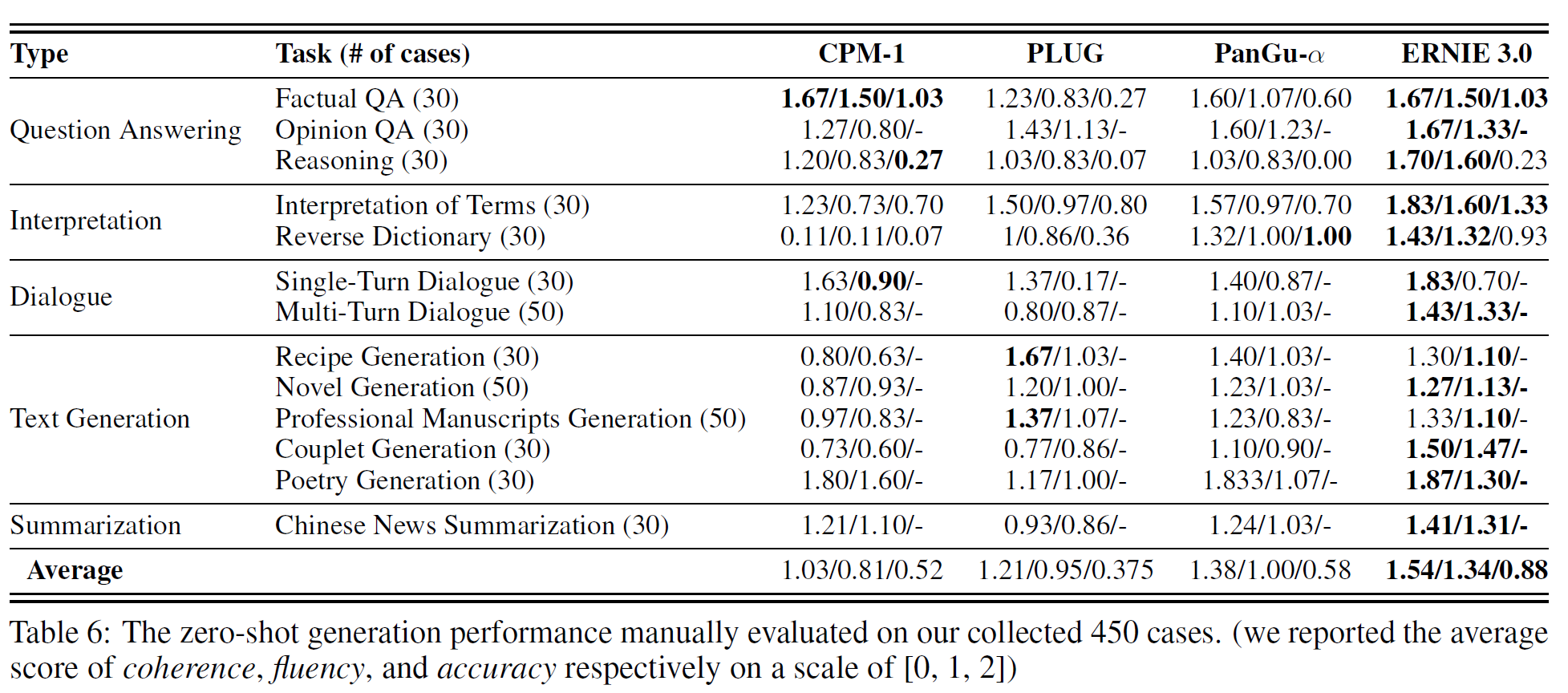
4.3.3 Case Study
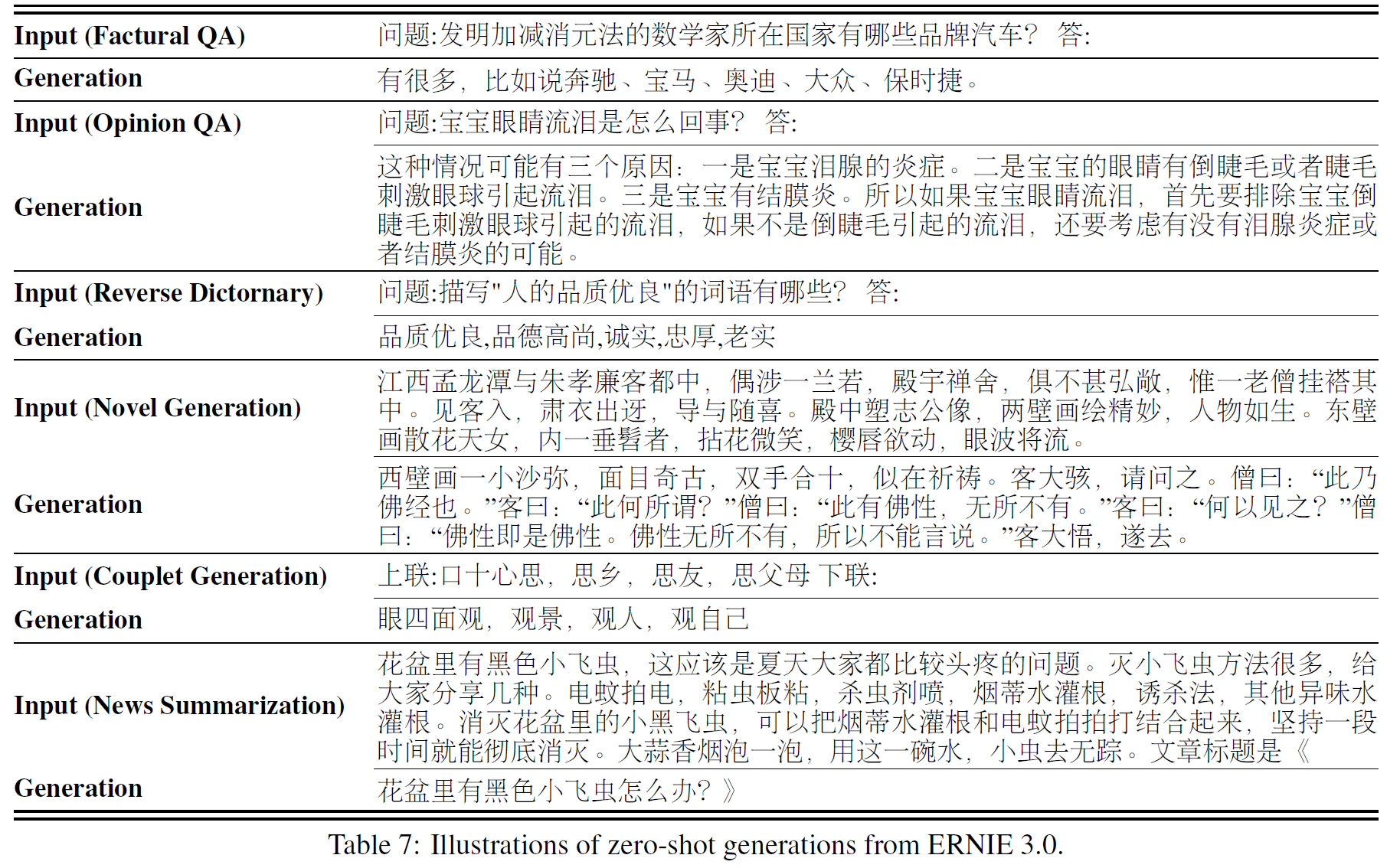
QA, Interpretation, Dialogue, Text Generation, Summarization 5종류의 13개 task에서 450개의 case를 모아 zero-shot 생성능력을 평가하였다. coherence, fluency, accuracy는 표 6에서 확인할 수 있고, 일부 예시는 아래 표 7에서 볼 수 있다. (중국어이다..) 세부는 표 8에서 볼 수 있다.
4.4 Experiments on SuperGLUE
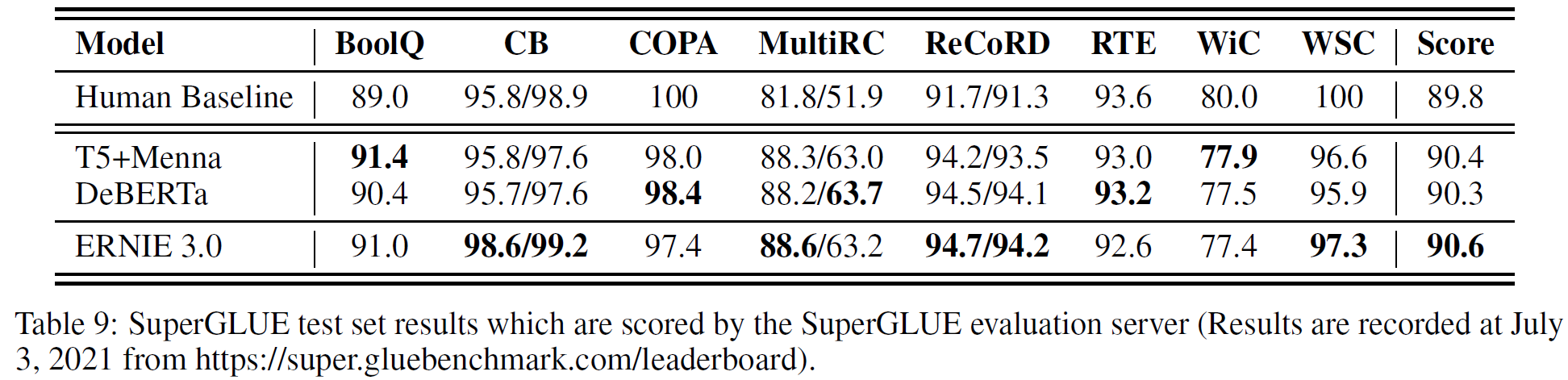
절반 정도에 해당하는 task에서 GLUE benchmark 1위 자리에 올랐다고 한다.
5. 분석(Analysis)
The Effectiveness of the Task-specific Representation Modules
다양한 사전학습 task 하에서 parameter를 공유하는 모델(원래는 공유하지 않는 모델)과 비교하였다. 통합 모델은 12 layers, 768 dims, 12 attention heads를 갖지만 원래 모델은 각 task당 3 layers, 256 dims, 4 attention heads를 갖는다. 이 두 모델을 갖고 사전학습 단계에서 NLG task의 perplexity를 비교한 결과가 아래 그림과 같다.
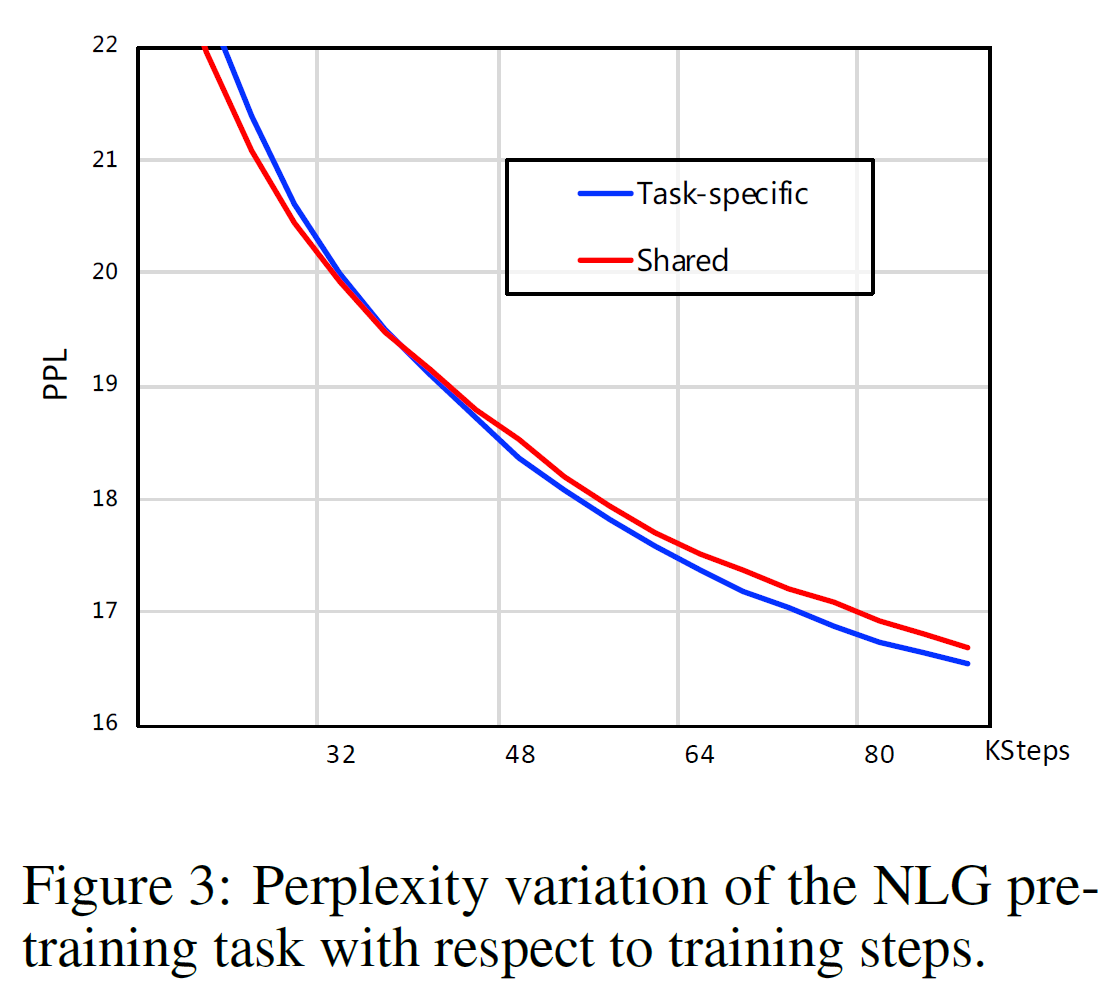
학습이 진행됨에 따라 task-specific module을 갖고 있는 것이 통합 모듈을 갖는 것보다 PPL이 점점 더 낮아지는 것을 볼 수 있다.
Universal Knowledge-Text Prediction
관계추출 task는 전형적인 지식 기반 task로 주어진 문장에서 언급된 2개의 entity 간의 관계를 예측하는 것이다. 구체적으로, 4개의 특수 token [HD], [\HD], [TL], [\TL]을 추가하여 head/tail entity를 구별할 수 있게 하고, 관계 분류기는 전술한 4개의 특수 token의 최종 표현의 합으로 수행된다. SanWen과 FinRE에서 측정한 결과 지식 강화전략은 관계추출에서 좋은 성능 향상을 보여준다.
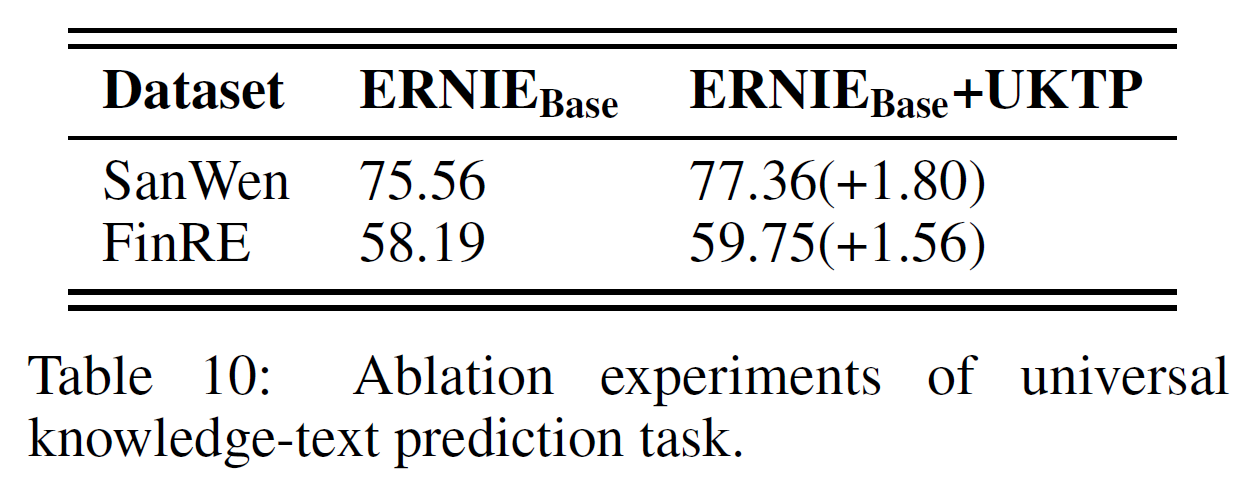
추가로, CKBQA에서 수행한 zero-shot 생성 실험도 UKTP task의 효과를 보여준다. KBQA task는 모델이 지식 그래프에 기반해서 정답과 그 이유를 들도록 요구하는 task로 지식학습 능력을 평가하는 데 적합하다. zero-shot 세팅으로 "QUESTION: $QUESTION? ANSWER:" 형식을 사용, CKBQA데이터셋에서 SOTA 모델과 ERNIE 3.0을 비교하였다. 표 5에서 보듯이 ERNIE 3.0은 타 모델을 능가한다.
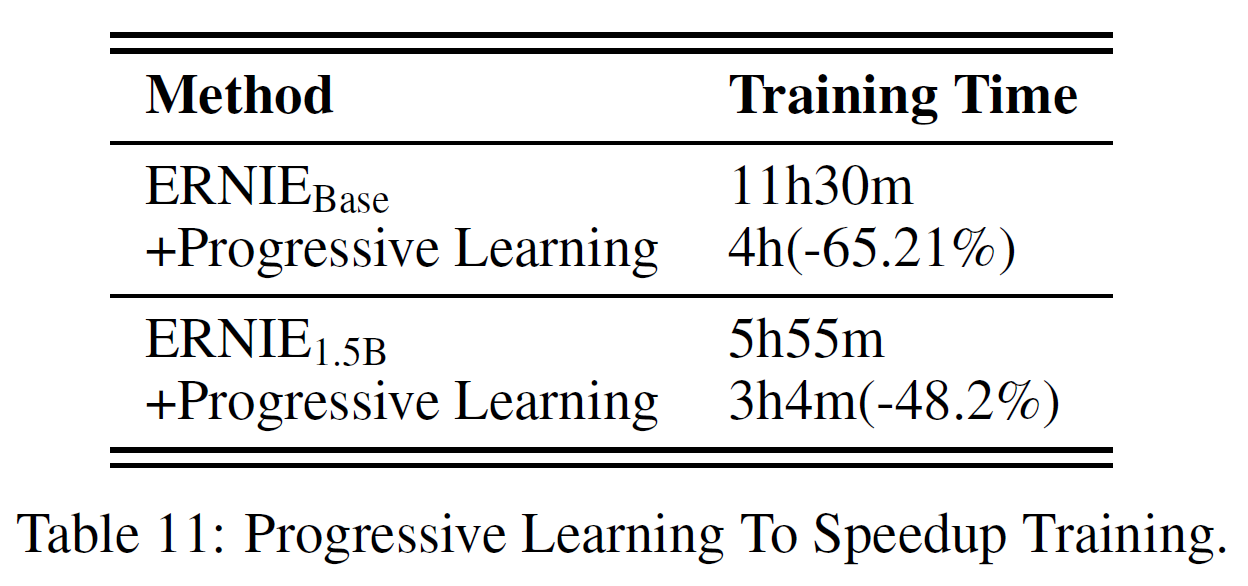
Progressive Learning to Speed up Convergence
학습 수렴속도를 보기 위해 ERNIE-Base, ERNIE-1.5B와 비교한다. ERNIE-1.5B는 48 layers, 1536 dims, 24 attention heads를 갖는다. 학습 시간은 ERNIE 3.0의 loss 값과 동일해질 때까지의 시간으로 측정하였다. 표 11에서 보듯이 ERNIE-Base는 65.21%의 감소를, ERNIE-1.5B는 48.2%만큼 감소하있다. 2개의 세팅에서 모두 8개의 NVIDIA Tesla V100 GPU를 사용하였다.
- ERNIE-Base의 경우, batch size를 8에서 2048로 늘리고 sequence 길이는 128에서 512로 증가사킸고, learning rate는 0에서 1e-4로 선형 증가, dropout은 warmup stage 동안 0으로 고정하였다. ERNIE 1.5
- ERNIE-1.5B의 경우, batch size를 8에서 8192로 늘리고 learning rate는 0에서 6e-4로 선형 증가, dropout은 warmup stage 동안 0으로 고정하였다.
나머지 세팅은 ERNIE-Base와 같다.
6. 결론(Conclusion)
4TB의 대규모 말뭉치, 10B개의 parameter를 갖는 사전학습 framework ERNIE 3.0을 제안하였다. ERNIE 3.0은 auto-encoder, auto-regressive 네트워크를 통합한 사전학습 framework로 자연어이해, 생성, zero-shot 학습에서 모두 좋은 성능을 보였다.
참고문헌(References)
논문 참조!